Apple silicon M5, faster on device AI with MLX

Apple silicon M5, faster on device AI with MLX
The new M5 MacBook Pro is built for people who care about speed on their own machine. Apple’s latest chips add Neural Accelerators in the GPU and more memory bandwidth, so modern AI models can run faster, directly on your Mac.
Apple’s MLX framework sits on top of that hardware. It is the piece that makes it easy to run and experiment with large language models on Apple silicon, without needing to send data to a remote server.
Fenn uses MLX under the hood so it can take advantage of Apple silicon, including the new M5 chips, while keeping your file search private and on device.
MLX in simple terms
MLX is Apple’s open source array framework designed for Apple silicon.
In plain words:
It understands how to use the CPU, GPU, and now the Neural Accelerators in the M5.
It lets developers run and tune language models and other AI models directly on a Mac.
It takes advantage of unified memory, so data does not need to be copied back and forth between components.
You do not see MLX in your dock, but if you use an app that is built on it, you benefit from the speed and efficiency of Apple silicon without thinking about tensor shapes or kernels.
What M5 changes for on device AI
In the M5 MacBook Pro, Apple added Neural Accelerators in the GPU that are dedicated to matrix math. This is the core operation behind many AI models, including large language models.
With the latest macOS release, MLX can use those Neural Accelerators when you are on M5, which means:
Faster time to first response when a model runs on your Mac
Better performance on larger models, including quantized versions
Improved throughput for workloads that fit in unified memory
Apple’s own benchmarks show that, for a range of language models, M5 cuts the time to first token by several times compared to M4 in many cases, and also improves generation speed, especially when the model fits well in memory.
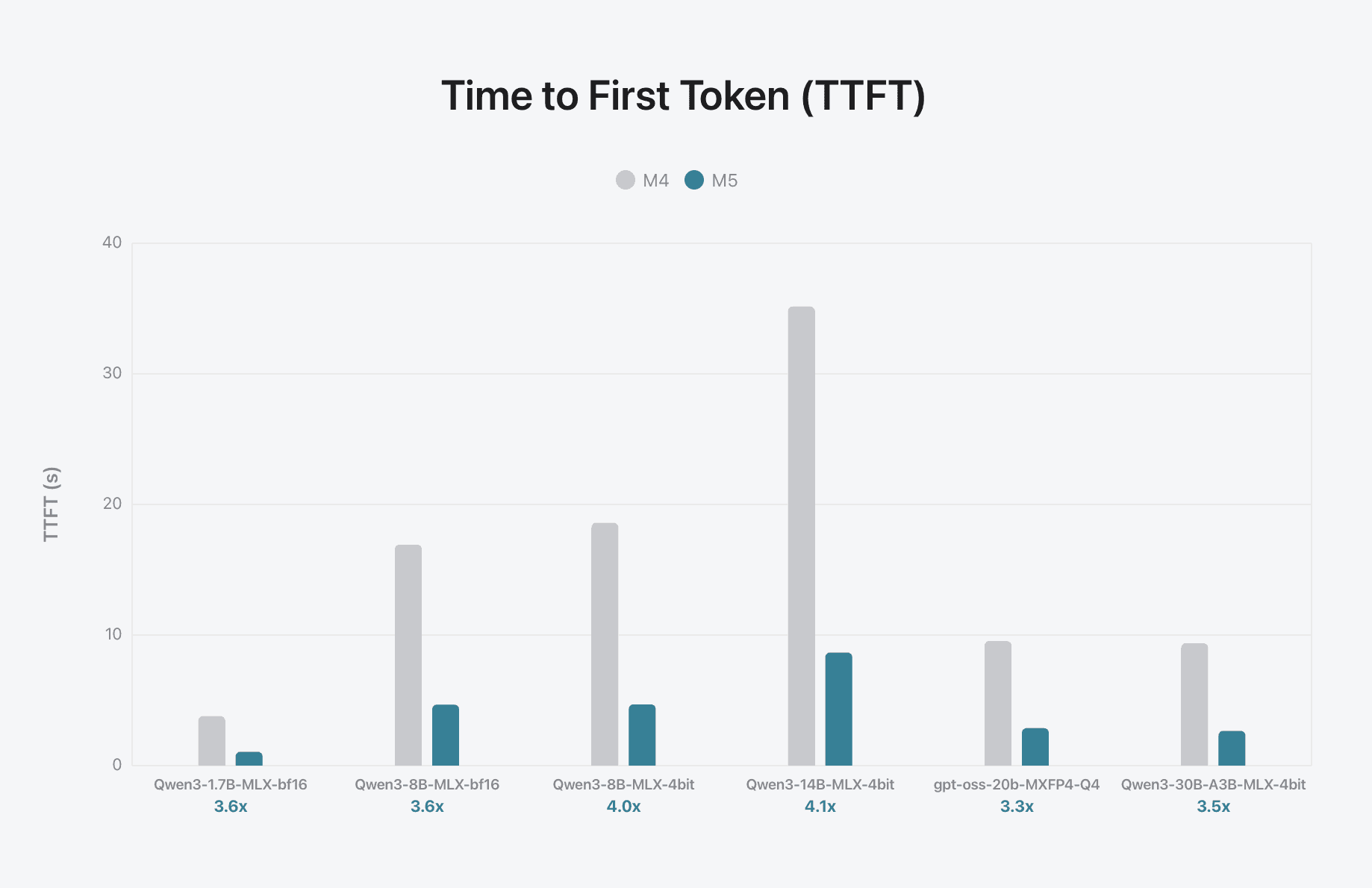
Source: https://machinelearning.apple.com/research/exploring-llms-mlx-m5
You do not have to understand the details to feel the effect. On an M5 Mac, AI workloads that once felt heavy become much more responsive.
How this helps Fenn users
Fenn is a file search engine for macOS that understands your content, PDFs, Office files, images with text, audio, video, and Apple Mail. It runs on device by default and uses MLX under the hood to take advantage of Apple silicon.
On an M5 Mac, this matters in two places:
Indexing and understanding your files
Agent Mode and heavier AI style queries
Faster indexing on powerful Macs
When you first point Fenn at your folders, it needs to read and understand your documents, images, audio, and video. On an M5:
Large libraries of PDFs and Office files are processed faster
Text is extracted and embedded more quickly
Image and screenshot understanding benefits from the improved hardware
The result is less time waiting for initial indexing and faster updates when you add new content.
Faster Agent Mode and semantic search
Agent Mode and semantic search rely on model based understanding. On an M5 Mac using MLX:
Complex questions that look across many files feel more responsive
Larger context windows and heavier prompts are more practical
Multi step queries (search plus lightweight analysis) complete faster
For example, queries like:
“All contracts that mention termination within 30 days, show the pages”
“Invoices from vendor X above 500 dollars in 2024, grouped by month”
“Spreads that show the teal gradient and mention Summer Lookbook”
become easier to run frequently, because the model work behind them is better served by the M5 hardware.
Agent Mode works best on higher memory Macs, especially when you keep many large files indexed. It also runs on 16 GB. If you want help tuning settings on your Mac, contact us.
What this looks like in daily work
Creatives with heavy assets
If you keep thousands of Photoshop, Illustrator, and InDesign exports, plus RAW images and reference boards:
Indexing completes faster on your M5 Mac
Searching for “hero image with teal gradient and tall headline” returns results quickly
Agent Mode can scan a whole project folder to list spreads that match a visual and text brief
Lawyers and contract heavy teams
If you manage folders full of contracts, scanned PDFs, and email threads:
Clause level search feels snappier, even across many PDFs
Agent Mode can triage contracts by termination, governing law, or liability caps more comfortably
Searching email plus contracts for a specific promise feels closer to realtime
Finance and ops
If your world is invoices, statements, models, and closing binders:
Large close folders are indexed more quickly
Queries like “invoices from vendor X above 500 dollars in 2024” or “documents that mention DSCR covenant” return faster
You can run richer Agent Mode questions during audits and reviews without slowing your Mac to a crawl
Researchers and product teams
If you live in dense PDFs, notes, and recordings:
Long reports index faster, including pages and figures
Model based search over notes and documents feels more interactive
Agent Mode can scan more material to summarize themes or surface key pages
Getting the most from an M5 Mac with Fenn
You do not need to change much to benefit from M5 and MLX, but a few habits help:
Keep macOS up to date
The Neural Accelerators in M5 are used by MLX on newer macOS releases, so updating keeps performance improvements flowing.Index the folders that matter most
Start with contracts, finance, creative projects, and research folders, rather than your entire disk. You get the biggest gains where you work every day.Use Semantic and Agent Mode for heavy questions
Simple filename lookups can stay in Keyword or Exact. Save Semantic and Agent Mode for questions that really benefit from AI understanding.Keep your Mac plugged in for big indexing jobs
When you point Fenn at a huge archive, plug in and let M5 do the work while you continue using your Mac.
Why powerful Mac users should care
If you invested in an M5 MacBook Pro or another modern Apple silicon machine, you already have a strong on device AI platform. MLX is how Apple exposes that power to developers. Fenn is how you turn it into something practical, private, and concrete in your day to day work.
You keep your data on your own Mac
You get faster indexing and faster answers
You can ask richer questions about your files, not just the web
Download Fenn for Mac. Private on device. Find the moment, not the file.
See also